Extreme Testing-Vision+Arch
- Gautam Divgi (Unlicensed)
- Sampath Priyankara
- Sundar Krishnamoorthy (Deactivated)
Extreme Testing: Vision/Architecture/Tasks Whiteboard
Gautam's comments
- Sampath's post on the openstack-operators list and responses
- http://lists.openstack.org/pipermail/openstack-operators/2017-August/014072.html
- Most of the responses suggest using Rally with os-faults - which is one of the main directions we are headed. So that's good.
- Rally has a bunch of features on the roadmap that we need but those are blocked due to one reason or the other. https://docs.google.com/a/mirantis.com/spreadsheets/d/16DXpfbqvlzMFaqaXAcJsBzzpowb_XpymaK2aFY2gA2g/edit#gid=0
- Multi scenarios is blocked
- Distributed workload is blocked
- There's a lot of discussion around some refactoring - which is allegedly super-hard because its breaking just about everything...
- They plan to add various features taken care of by shaker today - like vm workloads.
- Question: We may need to engage w/ the rally folks at the ptg on a proposed resolution.
- Concern - rally is building a fairly extensive orchestration mechanism
- But there are other orchestration mechanisms that may be better suited - e.g. Ansible (or anything else - not picky!!!)
Sample Workload used for performance testing
Admin: Create tenant & users
Net: Create network
Subnet: Create subnet in "net"
ListNet: list networks
BootVM: Create an instance
ListVM: List instances/VMs
Volume: create a cinder volume
ListVol: List cinder volumes
Attach: Attach cinder volumes to VM
Reboot: Reboot VM
Detach: Detach Cinder volume from VM
DelVM: delete VM
DelVol: Delete cinder volume
DelSubn: Delete subnet
DelNet: Delete network

There are also some heat templates used. But this is pretty much what happens for most things.
Stack to be used: IMHO - lets use either Mitaka or Newton. I'm partial towards Newton, but most may be on Mitaka today.
^^ In community, we have to focus on Master or RC1-3. Best case, n-2 release is possible. Because, n-3 is EOL. Mitaka became EOL since this release. (sampath)
Sundar's Comments
- Define reference architecture
- Define reference workload
- Define stack
- Define core components to test
Edited on 8/1/17
- Phase 1 (Focus on Openstack Summit Presentation - A small deliverable, Demo and PPT for high level Vision)
- Define reference architecture
- stick to one reference architecture and release
- Make assumptions when necessary and justify why it was made
- Pick the components you want to include as a part of the ref architecture - Minimum required to sustain a meaningful test for phase 1
- Pick one component that we are going to test - Ceph/Neturon etc for phase 1
- Define reference workload
- Simple is good. Pick load for the ONE component being tested
- Need not be real life representational for phase 1
- Define Test Framework (for phase 1)
- Define test framework for the ONE component being tested (highliten the relevant components alone in the big-picture diagram)
- Define discovery
- Define load injection parameters
- Define failure injection
- Define what metrics will be gathered
- Test Manager (just define/setup for extensibility for phase 1)
- (LAB) Perform test
- Setup Env
- Setup discovery (setup of environment - the map)
- Introduce load
- Introduce failure
- Gather metrics/Documents and findings
- Introduce test manager and automate the above testing, perform a testing to validate test manager
- Deliverables
- Draft reference architecture
- Draft workload definition
- Draft MOP of env setup and parameters
- Draft Test plan
- Draft results, metrics gathered and follow ups
- Draft Vision Document/PPT
- Define reference architecture
- Phase 2 (focus on Extending Phase 1 - Goal is to make a Specific Phase 1 to a Generic model)
- Define architecture
- Same as phase 1
- Add a component to test
- Define ref workload
- simple is good. Extend existing workload or add one for CURRENT component being tested
- Not representational for Phase 2
- Define Framework (As above in Phase 1)
- Accommodate the new component being tested
- Enable it under Test Manager
- **Now enable automated testing through test Manager for BOTH the components
- (LAB) Perform test
- Should be able to test for both Phase 1 and 2
- Document results
- Define architecture
- Phase 3
Problem Statement (Why needed?)
- Robustness/Resiliency of OpenStack at the CI/CD gates
- Developers can share re-creatable performance and resiliency experiments
- Easy to define scenarios and execute
- Should be verifiable via KPI and automated on reference architecture. There shouldn't be any eyeballing of graphs
- Better monitoring, SLA and failure models on reference deployment architectures
Vision Statement (How accomplished? – 5 main points already outlined in Wiki)
- Define test workflow
- Test frequency – not the entire suite can be run at each check in
- Find the minimal set that are critical for testing at each CI/CD gate
- Define test framework
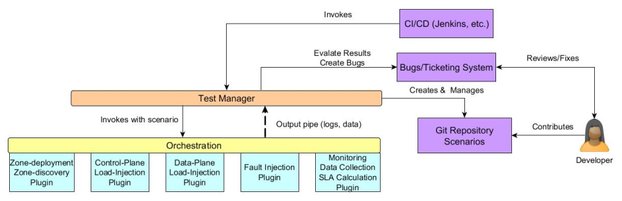
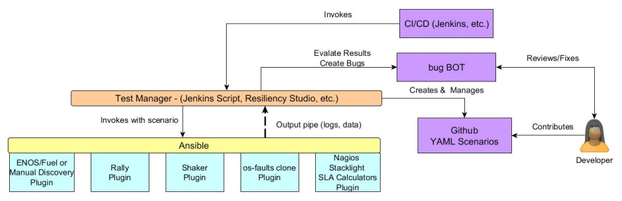
- Test Tools (preferable agentless: not ideal to have "failure injection" agents running on production/test sites)
- Deployment
- Create repeatable experiments
- Discovery
- Discovery a site – everything including h/w, underlay, etc.
- Load injection (Control & Data Plane)
- Rally: For control plane load injection
- Shaker: For data plane load injection
- Failure injection
- Os-faults: For failure injection
- Metrics gathering
- Need new tools – should be agentless/ssh/ansible based.
- Pipe metrics to test manager
- Deployment
- Test Tools (preferable agentless: not ideal to have "failure injection" agents running on production/test sites)
- Orchestration
- Ansible – create rally, shaker, os-faults and metrics gathering plugins
- Test Manager
- Resiliency Studio/Jenkins (AT&T Proposed – time to open source is Aug – Sept 2018)
- Start orchestrator runs
- Collect metrics
- Incorporate capability for SLA plugins
- SLA plugins will decide whether test is a success/failure
- Interact with GitHub/CI-CD environments
- Provide detailed logs and metrics for data
- Create bugs
- Orchestration
- Developer Tools
- Goal:
- Push what can be possible as far left into the development cycle
- Minimize resource utilization (financial & computational)
- Data Center Emulator
- Emulate reference architectures
- Run performance and failure injection scenarios
- Mathematically extrapolate for acceptable limits
- Goal:
- Define test scope & scenarios
- KPI/SLA
- What metrics are part of the KPI matrix
- Examples: Control Plane – API response time, Success Rate, RabbitMQ connection distribution, CPU/Memory utilization, I/O rate, etc.
- Examples: Data Plane – throughput, vrouter failure characteristics, storage failure characteristics, memory congestion, scheduling latency, etc.
- What are the various bounds?
- Examples: Control Plane - RabbitMQ connection distribution should be uniform within a certain std. deviation, API response times are lognormal distributed and not acceptable past 90 percentile, etc.
- Realistic Workload Models for control & data plane
- Realistic KPI models from operators
- Realistic outage scenarios
- What metrics are part of the KPI matrix
- Automated Test Case Generation
- Are there design & deployment templates that can be supplied so that an initial suite of scenarios is automatically generated?
- Top-Down assessment methodology to generate the scenarios – shouldn't burden developers with "paperwork".
- Performance
- Control Plane
- Data Plane
- Destructive
- Failure injection
- Scale
- Scale resources (cinder volumes, subnets, VMs, etc.)
- Concurrency
- Multiple requests on the same resource
- Operational Readiness
- What are we looking for here – just a shakeout to ensure a site is ready for operation? May be a subset of performance & resiliency tests?
- KPI/SLA
- Define reference architectures
- What are the reference architectures?
- H/W variety – where is it located?
- Deployment toolset for creating repeatable experiments – there is ENoS for container based deployments, what about other types?
- Deployment, Monitoring & Alerting templates
- Implementation Priorities
- Tackle Control Plane & Software Faults (rally + os-faults)
- Most code already there – need more plugins
- os-faults: More fault injection scenarios (degradations, core dumps, etc.)
- Rally: Randomized triggers, SLA extensions (e.g. t-test with p-values)
- Metrics gathering plugin
- Shaker enhancements (rally + shaker + os-faults)
- os-faults hooks mechanisms
- Storage, CPU/Memory (also cases with sr-iov, dpdk, etc.)
- os-faults for data plane software failures (cinder driver, vrouter, kernel stalls, etc.)
- Develop SLA measurement hooks
- os-faults underlay enhancements & data center emulator
- os-faults: Underlay crash & degradation code
- Data center emulator with ENoS to model underlay & software
- Traffic models & KPI measurement
- Realistic traffic models (CP + DP) and software to emulate the models
- Real KPI and scaled KPI to measure in virtual environments
- Tackle Control Plane & Software Faults (rally + os-faults)